Joined: 01/09/2017

![]() #2863504
-
03/03/2026 12:05:40
#2863504
-
03/03/2026 12:05:40
What is Context Window in LLM? Giải thích trong 2 phút
Góc nhìn nhanh: Trong vài năm qua, thuật ngữ "context window" xuất hiện thường xuyên khi nói về các mô hình ngôn ngữ lớn (LLM). Nói ngắn gọn, context window là lượng thông tin đầu vào mà một LLM có thể xử lý cùng lúc — từ câu hỏi người dùng, chuỗi hội thoại trước đó đến các đoạn văn cần phân tích. Khái niệm này quyết định được giới hạn độ dài cuộc hội thoại, khả năng theo dõi ngữ cảnh dài và cả cách các mô hình sinh văn bản giữ mạch nội dung.
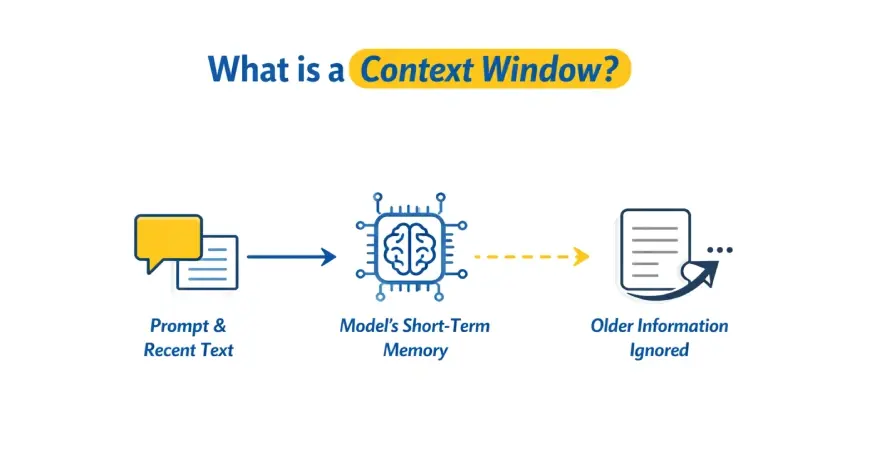
Tại sao context window quan trọng? Một context window đủ rộng giúp LLM nhớ các chi tiết trong đoạn hội thoại dài, tránh lặp ý và duy trì nhất quán khi tạo nội dung phức tạp như mã nguồn, bài báo kỹ thuật hay cốt truyện game. Nếu bạn vượt quá giới hạn này, mô hình không thể truy cập những phần văn bản đầu tiên nữa — điều này dẫn đến mất ngữ cảnh, câu trả lời mơ hồ hoặc yêu cầu phải tóm tắt lại thông tin. Trong ứng dụng thực tế, giới hạn này ảnh hưởng trực tiếp tới trải nghiệm người dùng: từ chatbot hỗ trợ khách hàng đến công cụ biên tập tự động và trợ lý viết mã.
Cách hoạt động cơ bản: Về mặt kỹ thuật, context window được đo bằng số token — một đơn vị ký tự/mã hóa do tokenizer của mô hình tạo ra. Một token có thể là một ký tự, một phần của từ hoặc một từ nguyên vẹn, tùy thuộc tokenizer. Khi bạn gửi yêu cầu đến LLM, tất cả các token của prompt và nội dung trước đó được tính vào quota của context window. Khi tổng số token vượt quá ngưỡng đã định, mô hình thường cắt bớt phần đầu của chuỗi (trong nhiều triển khai) khiến thông tin cũ bị mất.
Thực tế và xu hướng hiện nay: Các mô hình ban đầu có context window vài nghìn token, nhưng tiến bộ gần đây đã đẩy con số này lên hàng chục hoặc thậm chí hàng trăm nghìn token ở một số mô hình đặc thù. Việc mở rộng context window giúp xử lý tài liệu dài như sách, báo cáo kỹ thuật hoặc mã nguồn lớn mà không cần chia nhỏ nhiều lần. Tuy nhiên, tăng context window đi kèm chi phí tính toán và bộ nhớ cao hơn, đồng thời đòi hỏi tối ưu hóa kiến trúc và phần cứng.
Hạn chế và giải pháp tạm thời: Khi context window có giới hạn, các giải pháp thực tế được áp dụng gồm tóm tắt trước khi gửi, phân đoạn thông minh, lưu trữ trạng thái ngữ cảnh ngoài mô hình (context caching) hoặc sử dụng kỹ thuật retrieval-augmented generation (RAG) để truy vấn tài liệu liên quan thay vì đưa toàn bộ vào prompt. Những kỹ thuật này giúp cân bằng giữa chi phí và hiệu quả khi làm việc với dữ liệu dài.
Ứng dụng và khuyến nghị: Đối với nhà phát triển và người làm sản phẩm, việc hiểu rõ context window là điều cần thiết khi thiết kế trải nghiệm giao tiếp với LLM. Nên kiểm tra giới hạn token của mô hình bạn dùng, tối ưu prompt, và cân nhắc lưu trữ ngắn hạn các điểm mấu chốt thay vì đẩy toàn bộ lịch sử cuộc hội thoại. Trong bối cảnh game hoặc phần mềm, việc quản lý ngữ cảnh hiệu quả mang lại trải nghiệm NPC tự nhiên hơn, cốt truyện liên tục và hỗ trợ người chơi tốt hơn.
Đọc thêm: Bài viết tham khảo trên Analytics Vidhya cung cấp phân tích chi tiết hơn về context window: https://www.analyticsvidhya.com/blog/2026/01/context-window-in-llm/. Một số nguồn bổ sung để tham khảo gồm tài liệu chính thức và bài viết kỹ thuật của nhà cung cấp: OpenAI Guides và bài phân tích chuyên sâu từ Hugging Face: Hugging Face — Context Windows.
Tóm lại: Context window là thước đo then chốt của khả năng xử lý ngữ cảnh dài trong LLM. Hiểu và quản lý giới hạn này giúp tối ưu trải nghiệm, giảm chi phí tính toán và mở ra nhiều ứng dụng mới cho phần mềm và game hiện đại.
Tại sao context window quan trọng? Một context window đủ rộng giúp LLM nhớ các chi tiết trong đoạn hội thoại dài, tránh lặp ý và duy trì nhất quán khi tạo nội dung phức tạp như mã nguồn, bài báo kỹ thuật hay cốt truyện game. Nếu bạn vượt quá giới hạn này, mô hình không thể truy cập những phần văn bản đầu tiên nữa — điều này dẫn đến mất ngữ cảnh, câu trả lời mơ hồ hoặc yêu cầu phải tóm tắt lại thông tin. Trong ứng dụng thực tế, giới hạn này ảnh hưởng trực tiếp tới trải nghiệm người dùng: từ chatbot hỗ trợ khách hàng đến công cụ biên tập tự động và trợ lý viết mã.
Cách hoạt động cơ bản: Về mặt kỹ thuật, context window được đo bằng số token — một đơn vị ký tự/mã hóa do tokenizer của mô hình tạo ra. Một token có thể là một ký tự, một phần của từ hoặc một từ nguyên vẹn, tùy thuộc tokenizer. Khi bạn gửi yêu cầu đến LLM, tất cả các token của prompt và nội dung trước đó được tính vào quota của context window. Khi tổng số token vượt quá ngưỡng đã định, mô hình thường cắt bớt phần đầu của chuỗi (trong nhiều triển khai) khiến thông tin cũ bị mất.
Thực tế và xu hướng hiện nay: Các mô hình ban đầu có context window vài nghìn token, nhưng tiến bộ gần đây đã đẩy con số này lên hàng chục hoặc thậm chí hàng trăm nghìn token ở một số mô hình đặc thù. Việc mở rộng context window giúp xử lý tài liệu dài như sách, báo cáo kỹ thuật hoặc mã nguồn lớn mà không cần chia nhỏ nhiều lần. Tuy nhiên, tăng context window đi kèm chi phí tính toán và bộ nhớ cao hơn, đồng thời đòi hỏi tối ưu hóa kiến trúc và phần cứng.
Hạn chế và giải pháp tạm thời: Khi context window có giới hạn, các giải pháp thực tế được áp dụng gồm tóm tắt trước khi gửi, phân đoạn thông minh, lưu trữ trạng thái ngữ cảnh ngoài mô hình (context caching) hoặc sử dụng kỹ thuật retrieval-augmented generation (RAG) để truy vấn tài liệu liên quan thay vì đưa toàn bộ vào prompt. Những kỹ thuật này giúp cân bằng giữa chi phí và hiệu quả khi làm việc với dữ liệu dài.
Ứng dụng và khuyến nghị: Đối với nhà phát triển và người làm sản phẩm, việc hiểu rõ context window là điều cần thiết khi thiết kế trải nghiệm giao tiếp với LLM. Nên kiểm tra giới hạn token của mô hình bạn dùng, tối ưu prompt, và cân nhắc lưu trữ ngắn hạn các điểm mấu chốt thay vì đẩy toàn bộ lịch sử cuộc hội thoại. Trong bối cảnh game hoặc phần mềm, việc quản lý ngữ cảnh hiệu quả mang lại trải nghiệm NPC tự nhiên hơn, cốt truyện liên tục và hỗ trợ người chơi tốt hơn.
Đọc thêm: Bài viết tham khảo trên Analytics Vidhya cung cấp phân tích chi tiết hơn về context window: https://www.analyticsvidhya.com/blog/2026/01/context-window-in-llm/. Một số nguồn bổ sung để tham khảo gồm tài liệu chính thức và bài viết kỹ thuật của nhà cung cấp: OpenAI Guides và bài phân tích chuyên sâu từ Hugging Face: Hugging Face — Context Windows.
Tóm lại: Context window là thước đo then chốt của khả năng xử lý ngữ cảnh dài trong LLM. Hiểu và quản lý giới hạn này giúp tối ưu trải nghiệm, giảm chi phí tính toán và mở ra nhiều ứng dụng mới cho phần mềm và game hiện đại.